In the world of web automation, browser agents play a crucial role in tasks like testing, data scraping, monitoring, and simulation. Tools such as Selenium and Puppeteer allow developers to script browser behavior, mimicking user interactions like clicking buttons, filling forms, or navigating pages. However, as projects scale, running these agents sequentially can become a bottleneck, taking hours or even days for large datasets or extensive test suites.
This is where parallel execution comes in. By running multiple browser agents simultaneously, you can drastically reduce processing time, improve efficiency, and handle higher volumes of work. Imagine scraping data from thousands of web pages or testing a web app across various browsers—all at once rather than one by one. In this comprehensive guide, we'll explore how to achieve this in Python using Selenium and in Node.js using Puppeteer. We'll also dive into cloud-based platforms (like Kernel!) that simplify scaling parallelism without managing local infrastructure. These services handle the heavy lifting of browser orchestration, anti-detection, and resource allocation, making them ideal for production-grade automations. We'll cover setups, code examples, best practices, and potential pitfalls, aiming to equip you with the knowledge to implement parallel browser automation effectively. Whether you're a beginner automating simple tasks or an experienced developer optimizing workflows, this post will provide actionable insights :)
Why Run Browser Agents in Parallel?
Before diving into the ‘how-to,’ let's understand the why. Sequential execution means each browser agent runs one after another, which is fine for small-scale operations but inefficient for larger ones. For instance, if a single scraping task takes 10 seconds and you have 100 pages, sequential mode would take over 16 minutes. In parallel with 10 agents, it could finish in about 1.6 minutes, assuming sufficient hardware resources.
sequential execution vs multiple agents
Key benefits include:
- Time Savings: Distribute workloads across multiple cores or processes, accelerating completion.
- Scalability: Handle more complex scenarios, like cross-browser testing (e.g., Chrome, Firefox, Edge) or multi-user simulations.
- Resource Optimization: Modern machines with multi-core CPUs can run several instances without maxing out, especially in headless mode (no visible UI).
- Real-World Use Cases: Automated testing in CI/CD pipelines, web scraping for data analysis, monitoring stock prices across sites, or load testing by simulating concurrent users.
However, parallelism isn't without challenges. It requires careful management of resources like CPU, memory, and network bandwidth to avoid crashes or slowdowns. Over-parallelizing can lead to diminishing returns due to overhead from context switching or browser limitations. This is where cloud platforms shine, offloading these concerns to managed services.
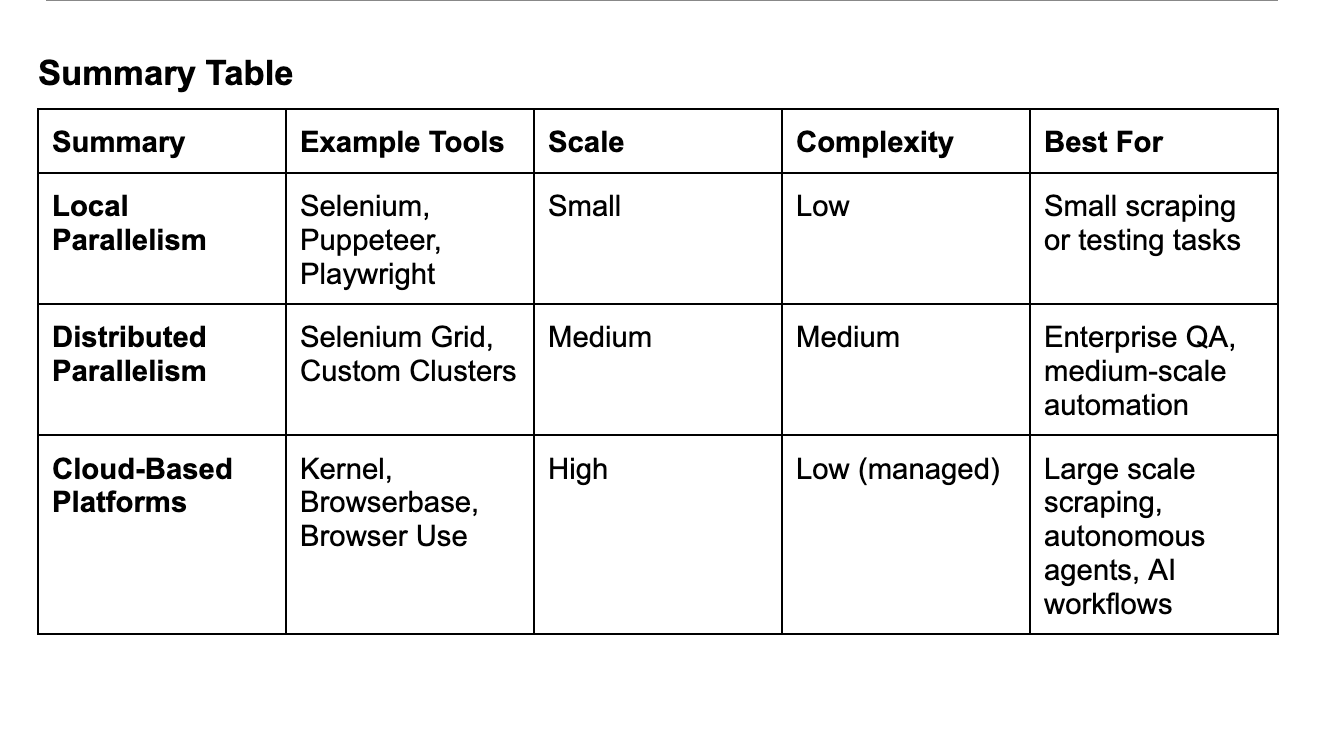
The Three Main Ways to Run Multiple Browser Agents in Parallel
When it comes to scaling browser automation, there are three distinct approaches, each suited to different needs, resources, and complexity levels.

Running Multiple Agents in Parallel
1. Local Parallelism (Selenium / Puppeteer / Playwright)
This is the most basic method: run multiple browser instances on a single machine or server.
How it works:
- Each agent is a separate headless browser instance
- Controlled via libraries like Puppeteer, Playwright, or Selenium
- Multiple agents run concurrently using threads, processes, or async tasks
Pros:
- Full control over browser behavior
- Minimal external dependencies
- Great for prototyping or small-scale tasks
Cons:
- Limited by your machine’s CPU and RAM
- Risk of crashes if too many browsers are open
- Manual orchestration is needed for retries and failures
Best for: testing, small scraping tasks, or quick experiments.
2. Distributed Parallelism (Selenium Grid / Custom Cluster)
When local parallelism hits its limits, the next step is distributed execution.
How it works:
- Multiple machines or servers run browser instances
- A central hub (like Selenium Grid) manages task distribution
- Agents can scale horizontally across servers
Pros:
- Handles more agents than a single machine
- Centralized orchestration and monitoring
- Reduces local resource strain
Cons:
- Setup and maintenance overhead
- Requires network configuration and server management
- Scaling beyond dozens or hundreds of browsers gets complex
Best for: enterprise-level testing, QA pipelines, or medium-scale automation projects.
3. Cloud-Based Platforms (Kernel / Browserbase / Browser Use)
For maximum scalability and minimal infrastructure headache, cloud-based platforms are the modern solution.
How it works:
- Agents run in the cloud and are accessed via API or SDK
- Providers like Kernel, Browserbase, and Browser Use handle provisioning, concurrency, retries, and resource allocation
- Kernel adds the capability for intelligent agents with memory, reasoning, and task orchestration
Pros:
- Virtually unlimited scale — run hundreds or thousands of agents
- Automatic orchestration, retries, and monitoring
- Some platforms support AI-driven decision-making and long-term memory
Cons:
- Slight learning curve for the API/SDK
- Cost scales with concurrency and usage
Best for: large-scale scraping, AI-driven autonomous agents, multi-step workflows, or any project where managing infrastructure is a distraction.
How To Set Up With Each Of The Three Methods
How-To 1: Local Parallelism with Selenium in Python
Objective: Run multiple Selenium browser instances in parallel on a single machine using Python’s multiprocessing module to scrape page titles from multiple URLs.
Steps:
- 1Install Prerequisites:
- Install Python (3.6+).
- Install Selenium: pip install selenium.
- Download and place a browser driver (e.g., chromedriver for Chrome) in your system PATH.
- 2Write a Script for Parallel Execution:
- Use multiprocessing.Pool to distribute tasks across processes, each running a headless Chrome instance.
- 3Execute and Monitor:
- Run the script and ensure your machine has enough resources (e.g., 4-8GB RAM for 4 parallel browsers).
Code Example:
import multiprocessing
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def scrape_page(url):
options = Options()
options.headless = True # Run without UI
driver = webdriver.Chrome(options=options)
try:
driver.get(url)
title = driver.title
except Exception as e:
title = f"Error: {str(e)}"
finally:
driver.quit()
return title
if __name__ == "__main__":
urls = [
"https://example.com",
"https://google.com",
"https://wikipedia.org",
]
# Adjust 'processes' based on available CPU cores
with multiprocessing.Pool(processes=4) as pool:
results = pool.map(scrape_page, urls)
print("Page Titles:", results)Key Considerations:
- Resource Limits: Each Chrome instance uses ~100-500MB RAM. Limit processes to half your CPU cores (e.g., 4 on an 8-core machine) to avoid crashes.
- Error Handling: The try-except block catches network or timeout errors, ensuring one failure doesn’t stop the pool.
- Scalability: Best for small-to-medium tasks (10-50 URLs). For larger tasks, consider more robust methods.
- Anti-Bot: Add manual proxy rotation or user-agent randomization if scraping protected sites.
Why Use This?: Ideal for quick prototyping or small-scale automation on a local machine, with no external costs.
How-To 2: Distributed Parallelism with Selenium Grid
Objective: Distribute browser automation tasks across multiple machines using Selenium Grid to run parallel tests or scraping tasks.
Steps:
- 1Set Up Selenium Grid:
- Download the Selenium Server JAR from the official Selenium website.
- Start the hub: java -jar selenium-server-standalone.jar hub.
- Start nodes on the same or different machines: java -jar selenium-server-standalone.jar node --hub http://<hub-ip>:4444/grid/register.
- 2Write a Script to Use the Grid:
- Use webdriver.Remote to connect to the hub, which distributes tasks to nodes.
- 3Run in Parallel:
- Use Python’s multiprocessing or a testing framework like TestNG (for Java) to send tasks to the hub concurrently.
Code Example:
import multiprocessing
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
def scrape_page(url):
driver = webdriver.Remote(
command_executor='http://localhost:4444/wd/hub', # Selenium Grid Hub address
desired_capabilities=DesiredCapabilities.CHROME
)
try:
driver.get(url)
title = driver.title
except Exception as e:
title = f"Error: {str(e)}"
finally:
driver.quit()
return title
if __name__ == "__main__":
urls = [
"https://example.com",
"https://google.com",
"https://wikipedia.org",
]
# Adjust the number of processes based on CPU cores
with multiprocessing.Pool(processes=4) as pool:
results = pool.map(scrape_page, urls)
print("Page Titles:", results)
Key Considerations:
- Setup Complexity: Requires configuring hub and nodes; cloud nodes (e.g., AWS EC2) simplify scaling but add cost.
- Scalability: Can handle 100s of agents across multiple machines, ideal for cross-browser testing.
- Resource Management: Ensure nodes have sufficient resources; monitor hub logs for bottlenecks.
- Anti-Bot: Manual proxy setup needed, similar to local parallelism.
Why Use This?: Perfect for large-scale testing (e.g., cross-browser, cross-device) in CI/CD pipelines or distributed environments.
How-To 3: Cloud-Based Platforms
Objective: Platforms like Kernel, Browserbase, and BrowserUse all are top cloud-based options for running multiple browser agents in parallel. Let’s break down using Kernel (that’s us!):
Steps:
- 1Sign Up and Get API Access:
- Create an account with Kernel (visit https://www.onkernel.com/ for API details or sign-up instructions).
- Obtain your API key or SDK credentials from the Kernel dashboard.
- 2Install SDK and Dependencies:
- Install Kernel’s Python SDK: pip install kernel.
- Install Playwright for browser control: pip install playwright and run playwright install to set up browsers.
- 3Write a Script for Parallel Execution:
- Use Kernel’s SDK to create multiple browser sessions.
- Leverage Python’s asyncio.gather to run tasks concurrently, connecting each session to Playwright for automation.
- 4Run and Monitor:
- Execute the script and use Kernel’s dashboard for session telemetry (e.g., replays, logs) to debug or optimize.
Code Example:
import asyncio
from kernel import Kernel
from playwright.async_api import async_playwright
async def scrape_with_kernel(urls):
kernel = Kernel(api_key="your_kernel_api_key") # Replace with your actual API key
async with async_playwright() as p:
tasks = []
async def run_task(url):
browser = await kernel.browsers.create() # Create a cloud browser session
try:
playwright_browser = await p.chromium.connect_over_cdp(browser.cdp_ws_url)
page = await playwright_browser.new_page()
await page.goto(url)
title = await page.title()
return title
except Exception as e:
return f"Error: {str(e)}"
finally:
await playwright_browser.close()
for url in urls:
tasks.append(run_task(url))
results = await asyncio.gather(*tasks, return_exceptions=True)
return results
# Example usage
if __name__ == "__main__":
urls = [
"https://example.com",
"https://google.com",
"https://wikipedia.org",
]
results = asyncio.run(scrape_with_kernel(urls))
print("Page Titles:", results)
Key Considerations:
- Scalability: Kernel’s cloud infrastructure scales to hundreds or thousands of sessions, with browsers spinning up in under 300ms, ideal for large-scale tasks.
- Anti-Bot Features: Built-in residential proxies, CAPTCHA solvers, and fingerprint randomization make Kernel excellent for scraping protected sites without manual configuration.
- Cost: Pay-as-you-go pricing (check x.ai/api for details). Monitor usage via the dashboard to manage costs.
- Ease of Use: Minimal setup with the SDK; integrates seamlessly with Playwright or Puppeteer for flexible automation.
- Telemetry: Kernel provides session replays and logs, simplifying debugging for failed tasks.
- Use Case: Perfect for production-grade web scraping, AI-driven browser agents, or high-volume automation requiring stealth and reliability.
Comparison to Other Platforms:
- Browserbase: Similar cloud-based approach with managed proxies and session recording, but emphasizes broader framework support (e.g., Stagehand for AI tasks). Pricing starts at ~$20/month for hobbyists.
- Browser Use: Focuses on AI-native automation using vision-based models (e.g., GPT-4o-computer-use), often paired with backends like Browserbase. Best for dynamic, unreliable websites but less focused on raw browser speed compared to Kernel.
Why Use Kernel?: Kernel’s ultra-fast browser spin-up, robust anti-bot measures, and seamless scaling make it ideal for production environments, especially for scraping or agent-based tasks where speed and stealth are critical. It eliminates local hardware management and simplifies parallelism with a developer-friendly API.
Best Practices for Parallel Browser Agents
Regardless of the tool or platform, follow these guidelines:
- Headless Mode Always: Reduces UI overhead and allows more instances.
- Monitor Resources: Use tools like htop (Linux) or Task Manager; on cloud platforms, leverage built-in dashboards.
- Handle Failures Gracefully: Implement retries for network errors. In Selenium, use WebDriverWait; in Puppeteer, try-catch around awaits; platforms like Kernel offer automatic retries.
- Avoid Over-Parallelization: Test empirically—more isn't always better due to browser limits (e.g., Chrome caps at ~10-15 instances per machine locally, but cloud scales higher).
- Use Cloud Services: For massive scale, integrate with BrowserStack, Sauce Labs, AWS Lambda, or the platforms mentioned above. They provide on-demand browsers without local hardware constraints.
- Legal and Ethical Considerations: Ensure compliance with site terms; use delays to avoid DDoS-like behavior.
- Testing in CI/CD: Tools like TestNG (for Selenium Java) or Jest (for Puppeteer) support parallel configs out-of-the-box.
Challenges and Solutions
Common issues include:
- Resource Exhaustion: Solution: Limit concurrency and use lightweight options (e.g., disable images in Puppeteer with page.setRequestInterception); cloud platforms auto-scale.
- Flaky Tests: Parallelism can introduce race conditions; ensure tests are independent.
- Detection by Sites: Rotate IPs/proxies and randomize behaviors—Kernel and Browserbase excel here.
- Debugging: Log worker IDs and use session replays from platforms for traceability.
It’ll be interesting to see how challenges and bugs change as the technology continues to evolve in this space.
Conclusion
Running multiple browser agents in parallel transforms slow, linear automation into a high-throughput powerhouse. With Selenium in Python, leverage multiprocessing for isolated, efficient execution. In Node.js with Puppeteer, harness async promises or clusters for seamless concurrency. For effortless scaling, platforms like Kernel make production parallelism a breeze. Start small, monitor performance, and scale as needed—whether locally or in the cloud. Experiment with the examples here, and adapt them to your needs. Happy automating!